
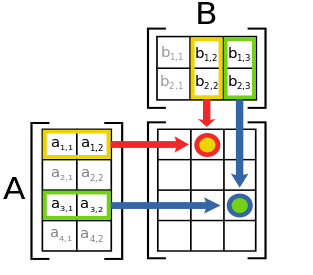
در این مثال روش ضرب دو ماتریس با استفاده از GPU را مشاهده می کنید:
// You might need to change this header based on your install: // You might need to change this header based on your install: #include <CL/cl.h> #include <string.h> #include <stdio.h> #include <stdlib.h> #include <iostream> #include <string> #include <fstream> #include <time.h> #include <windows.h> #define SUCCESS 0 #define FAILURE 1 using namespace std; #pragma comment(lib, "OpenCl.lib") static void check_error(cl_int error, char* name) { if (error != CL_SUCCESS) { fprintf(stderr, "Non-successful return code %d for %s. Exiting.\n", error, name); exit(1); } }
//برای دیدن کد کامل، ادامه مطلب را ببینید
//We assume the matrix dimensions are divisible by 16 const int coef = 100; const int hA = coef*16; const int wA = coef*16; const int hB = coef*16; const int wB = coef*16; const int hC = coef*16; const int wC = coef*16; float A[hA][wA] = { 0 }; float B[hB][wB] = { 0 }; float C[hC][wC] = { 0 }; //in second inline double StopWatch(int start0stop1 = 0, bool showMessage = false) { static LARGE_INTEGER swFreq = { 0, 0 }, swStart, swStop; static const double TwoPow32 = pow(2.0, 32.0); if (!swFreq.LowPart) QueryPerformanceFrequency(&swFreq); double result = -1; if (start0stop1 == 0) QueryPerformanceCounter(&swStart); else { QueryPerformanceCounter(&swStop); if (swFreq.LowPart == 0 && swFreq.HighPart == 0) return -1; else { result = (double)((swStop.HighPart - swStart.HighPart)*TwoPow32 + swStop.LowPart - swStart.LowPart); if (result < 0) result += TwoPow32; result /= (swFreq.LowPart + swFreq.HighPart*TwoPow32); } if (showMessage) { char s[25] = {0}; sprintf(s, "Time (s): %.4f", result); MessageBox(NULL, s, "Elapsed Time", 0); } } return result; }
void createMatrices() { for (size_t i = 0; i < hA; i++) for (size_t j = 0; j < wA; j++) { A[i][j] = rand() / (float)RAND_MAX; } for (size_t i = 0; i < hB; i++) for (size_t j = 0; j < wB; j++) { B[i][j] = rand() / (float)RAND_MAX; } } /* convert the kernel file into a string */ int convertToString(const char *filename, std::string& s) { size_t size; char* str; std::fstream f(filename, (std::fstream::in | std::fstream::binary)); if (f.is_open()) { size_t fileSize; f.seekg(0, std::fstream::end); size = fileSize = (size_t)f.tellg(); f.seekg(0, std::fstream::beg); str = new char[size + 1]; if (!str) { f.close(); return 0; } f.read(str, fileSize); f.close(); str[size] = '\0'; s = str; delete[] str; return 0; } cout << "Error: failed to open file\n:" << filename << endl; return FAILURE; } void cpu_multiply() { // Iterate over the rows of Matrix A for (int i = 0; i < hA; i++) { // Iterate over the columns of Matrix B for (int j = 0; j < wB; j++) { C[i][j] = 0; // Multiply and accumulate the values in the current row // of A and column of B for (int k = 0; k < wA; k++) { C[i][j] += A[i][k] * B[k][j]; } } } } void showResult() { return; for (size_t i = 0; i < hA; i++) { printf("\n"); for (size_t j = 0; j < wA; j++) { printf(" %.2f", C[i][j]); //A[i][j] = rand() / (float)RAND_MAX; } } /*for (size_t i = 0; i < hB; i++) for (size_t j = 0; j < wB; j++) { B[i][j] = rand() / (float)RAND_MAX; }*/ } int main(int argc, char const *argv[]) { srand(time(0)); createMatrices(); StopWatch(0); cpu_multiply(); StopWatch(1, 1); showResult(); printf("\n-------------------------------"); ////////////////////////////////////////////////////// //Step 1: Set Up Environment cl_int ciErrNum; // Use the first platform cl_platform_id platform; ciErrNum = clGetPlatformIDs(1, &platform, NULL); // Use the first device cl_device_id device; ciErrNum = clGetDeviceIDs( platform, CL_DEVICE_TYPE_ALL, 1, &device, NULL); cl_context_properties cps[3] = { CL_CONTEXT_PLATFORM, (cl_context_properties)platform, 0 }; // Create the context cl_context ctx = clCreateContext( cps, 1, &device, NULL, NULL, &ciErrNum); // Create the command queue cl_command_queue myqueue = clCreateCommandQueue( ctx, device, 0, &ciErrNum); ////////////////////////////////////////////////////// //Step 2: Declare Buffers and Move Data // We assume that A, B, C are float arrays which // have been declared and initialized // Allocate space for Matrix A on the device ////////////////////////////////////////////////////// //Step 3: Runtime Kernel Compilation const char *filename = "MatMul_Kernel.cl"; string sourceStr; int status = convertToString(filename, sourceStr); const char *source = sourceStr.c_str(); size_t sourceSize[] = { strlen(source) }; cl_program myprog = clCreateProgramWithSource(ctx, 1, &source, sourceSize, &ciErrNum); // Compile the program. Passing NULL for the �device_list’ // argument targets all devices in the context ciErrNum = clBuildProgram(myprog, 0, NULL, NULL, NULL, NULL); // Create the kernel cl_kernel mykernel = clCreateKernel( myprog, "simpleMultiply", &ciErrNum); ////////////////////////////////////////////////////// StopWatch(0); //both of the folowings are true #if 0 cl_mem bufferA = clCreateBuffer(ctx, CL_MEM_READ_ONLY, wA*hA * sizeof(float), NULL, &ciErrNum); // Copy Matrix A to the device ciErrNum = clEnqueueWriteBuffer(myqueue, bufferA, CL_TRUE, 0, wA*hA * sizeof(float), (void *)A, 0, NULL, NULL); #else cl_mem bufferA = clCreateBuffer(ctx, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, wA*hA * sizeof(float), (void *)A, &ciErrNum); #endif // Allocate space for Matrix B on the device cl_mem bufferB = clCreateBuffer(ctx, CL_MEM_READ_ONLY, wB*hB * sizeof(float), NULL, &ciErrNum); // Copy Matrix B to the device ciErrNum = clEnqueueWriteBuffer(myqueue, bufferB, CL_TRUE, 0, wB*hB * sizeof(float), (void *)B, 0, NULL, NULL); // Allocate space for Matrix C on the device cl_mem bufferC = clCreateBuffer(ctx, CL_MEM_WRITE_ONLY, hA*wB * sizeof(float), NULL, &ciErrNum); //Step 4: Run the Program // Set the kernel arguments clSetKernelArg(mykernel, 0, sizeof(cl_mem), (void *)&bufferC); clSetKernelArg(mykernel, 1, sizeof(cl_int), (void *)&wA); clSetKernelArg(mykernel, 2, sizeof(cl_int), (void *)&hA); clSetKernelArg(mykernel, 3, sizeof(cl_int), (void *)&wB); clSetKernelArg(mykernel, 4, sizeof(cl_int), (void *)&hB); clSetKernelArg(mykernel, 5, sizeof(cl_mem), (void *)&bufferA); clSetKernelArg(mykernel, 6, sizeof(cl_mem), (void *)&bufferB); // Set local and global workgroup sizes //We assume the matrix dimensions are divisible by 16 size_t localws[2] = { 16, 16 }; size_t globalws[2] = { wC, hC };//global work size // Execute the kernel ciErrNum = clEnqueueNDRangeKernel(myqueue, mykernel, 2, NULL, globalws, localws, 0, NULL, NULL); ////////////////////////////////////////////////////// //Step 5: Obtain Results to Host // Read the output data back to the host ciErrNum = clEnqueueReadBuffer( myqueue, bufferC, CL_TRUE, 0, wC*hC*sizeof(float), (void *)C, 0, NULL, NULL); StopWatch(1, 1); showResult(); return 0; }
کد کرنل - MatMul_Kernel.cl
// widthA = heightB for valid matrix multiplication __kernel void simpleMultiply( __global float* outputC, int widthA, int heightA, int widthB, int heightB, __global float* inputA, __global float* inputB) { //Get global position in Y direction int row = get_global_id(1); //printf("widthC: %d\n", get_global_size(0)); //printf("heightC: %d\n", get_global_size(1)); //printf("Core #%d\n", get_global_id(0)); //Get global position in X direction int col = get_global_id(0); float sum = 0.0f; //Calculate result of one element of Matrix C for (int i = 0; i < widthA; i++) { sum += inputA[row*widthA + i] * inputB[i*widthB + col]; } outputC[row*widthB + col] = sum; }